工作中需要自建一个简单的离线监控平台,车上收集的collectd数据会通过ETL平台提取,上传至时序数据库,然后由grafana展示。
原先这个项目采用的是opentsdb,但是其读写性能不太好,对hbase也有依赖,运维繁琐。业务场景对数据可用性要求不是那么高,即使数据丢了重新跑一下ETL任务即可。综合以上,我自己选了先前比较火热的influxdb作为时序数据库。
主+备设计
influxdb选用2.4开源版本(oss),grafana选用9.0开源版本。因为influxdb的开源版本只支持单点,不支持集群,业务场景也没必要上集群,因此就没有上云,直接用了物理机。
主机选的是8TB NVME+256G内存+64核,备机是旧的2TB NVME+128G内存+48核,性能都绰绰有余了。
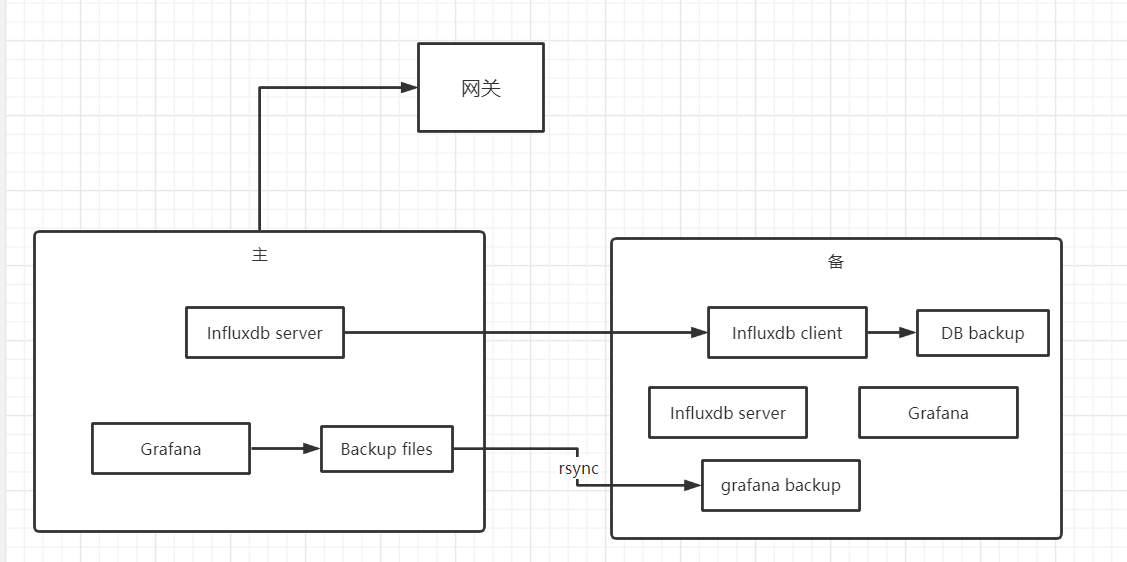
上图有几个需要注意的地方:
- 网关用于对外统一服务接入。假设主挂了切备,只需要改网关配置,用户不需要修改。
- influxdb的client可以远程直接备份全部内容,所以没有使用rsync。而grafana只能手动copy数据库文件,所以就用了rsync。其实grafana可以单独接数据库做高可用,但是思来想去,感觉没必要。
- 备份是通过定时任务实现的。我们保存15个月的数据,算了一下大概1TB左右,备份一次要一天,所以一周全量备份一次。
Influxdb部署
直接rpm安装后,使用systemctl start influxdb即可启动。log是通过systemctl的log打出来的,在/var/log/message中。
注意修改influxdb的config,把数据存到数据盘。所有的配置都可以在:https://docs.influxdata.com/influxdb/v2.4/reference/config-options/ 找到。
grafana部署
也是直接rpm安装,使用systemctl启动。grafana默认不开启用户注册,注意修改配置。grafana配置都带注释,非常舒服。
写入数据
通过influxdb的write api写入数据:https://docs.influxdata.com/influxdb/v2.4/api/#operation/PostWrite
这里注意一个坑:api中的line protocol其实是有很多讲究的,比如metrics名字里如果出现空格,应该使用转义字符。https://docs.influxdata.com/influxdb/v2.4/reference/syntax/line-protocol/
稍微压测了一下,调用write api,每次调用写入几百-几千个data points,并发1200,主机cpu利用率在30%左右,固态硬盘在10%-20%之间晃悠,内存几乎不怎么占用,可以说influxdb的性能还是很好的。
Grafana读取数据
选择数据源->influxdb即可。这里有个巨坑:grafana默认通过influx sql获取数据,但是调用的api还是influxdb v1的,如果你像我一样使用的是最新的influxdb的话,需要提前执行一些命令,让你的bucket兼容v1,如官方文档所示:
Because InfluxQL uses the 1.x data model, a database and retention policy combination (DBRP) must be mapped to a bucket before it can be queried using InfluxQL.
https://docs.influxdata.com/influxdb/v2.4/query-data/influxql/?t=InfluxDB+API
你需要用官方cli tool这样做一下,把这个mapping创建了:
influx v1 dbrp create \
--db example-db \
--rp example-rp \
--bucket-id 00oxo0oXx000x0Xo \
--default随后就可以正常query了。